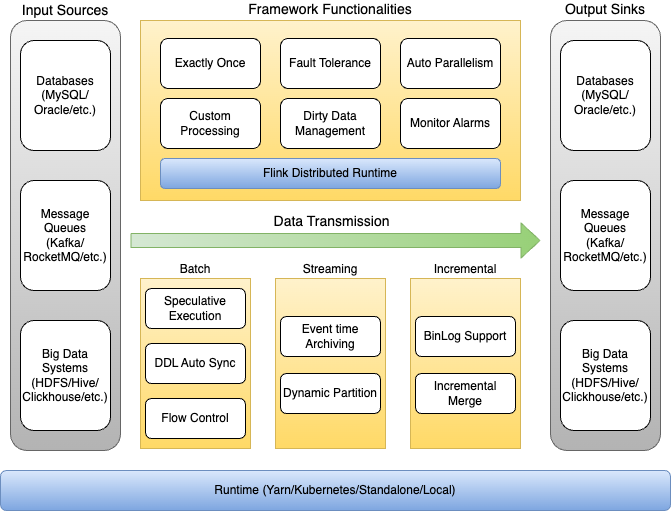
高性能本地缓存组件Caffeine Cache介绍
开发java后端项目时,经常会用到缓存技术,比如redis,memcahced都是用到频率比较高的缓存。不过除了这些分布式缓存之外,有些对性能要求比较高的项目也需要用到本地缓存及时,下面介绍一款本地缓存框架caffeine:
Caffeine 介绍
Caffeine 是基于 JAVA 8 的高性能缓存库。参考 Google Guava 的API对缓存框架重写,基于LRU算法实现,支持多种缓存过期策略。
Spring Boot 1.x版本中的默认本地缓存是Guava Cache。在 Spring5 (spring boot 2.x) 后,Spring 官方放弃了 Guava Cache 作为缓存机制,而是使用性能更优秀的 Caffeine 作为默认缓存组件,这对于Caffeine来说是一个很大的肯定。
为什么Spring会这样做呢?其实在Caffeine的Benchmarks里给出了非常靓的数据,针对读和写场景,与其他几个缓存框架进行了比较,Caffeine的性能表现非常突出。

项目集成
在 pom.xml 中添加 caffeine jar 包依赖:
<dependency>
<groupId>com.github.ben-manes.caffeine</groupId>
<artifactId>caffeine</artifactId>
<version>2.8.6</version>
</dependency>
初始化本地缓存类的Bean实例,并设置一系列配置参数,满足个性化业务场景需求。
public static LoadingCache<Long, User> loadingCache = Caffeine.newBuilder()
// 初始的缓存空间大小
.initialCapacity(5)
// 缓存的最大条数
.maximumSize(10)
.expireAfterWrite(4, TimeUnit.SECONDS)
.expireAfterAccess(10, TimeUnit.SECONDS)
.refreshAfterWrite(6, TimeUnit.SECONDS)
.recordStats()
//设置缓存的移除通知
.removalListener(new RemovalListener<Long, User>() {
@Override
public void onRemoval(@Nullable Long key, @Nullable User user, @NonNull RemovalCause removalCause) {
System.out.printf("Key: %s ,值:%s was removed!原因 (%s) \n", key, user, removalCause);
}
})
.build(id -> {
System.out.println("缓存未命中,从数据库加载,用户id:" + id);
return User.builder().id(id).userName("Lily").age(new Random().nextInt(20)).build();
});
参数说明:
initialCapacity 初始的缓存空间大小
maximumSize 缓存的最大条数
maximumWeight 缓存的最大权重
expireAfterAccess 最后一次写入或访问后,经过固定时间过期
expireAfterWrite 最后一次写入后,经过固定时间过期
refreshAfterWrite 写入后,经过固定时间过期,下次访问返回旧值并触发刷新
weakKeys 打开 key 的弱引用
weakValues 打开 value 的弱引用
softValues 打开 value 的软引用
recordStats 缓存使用统计
expireAfterWrite 和 expireAfterAccess 同时存在时,以 expireAfterWrite 为准。
weakValues 和 softValues 不可以同时使用。
maximumSize 和 maximumWeight 不可以同时使用。
构造LoadingCache对象,里面提供了很多方法来操作缓存,比如 getIfPresent 、put、invalidate等,详细可以参考下图: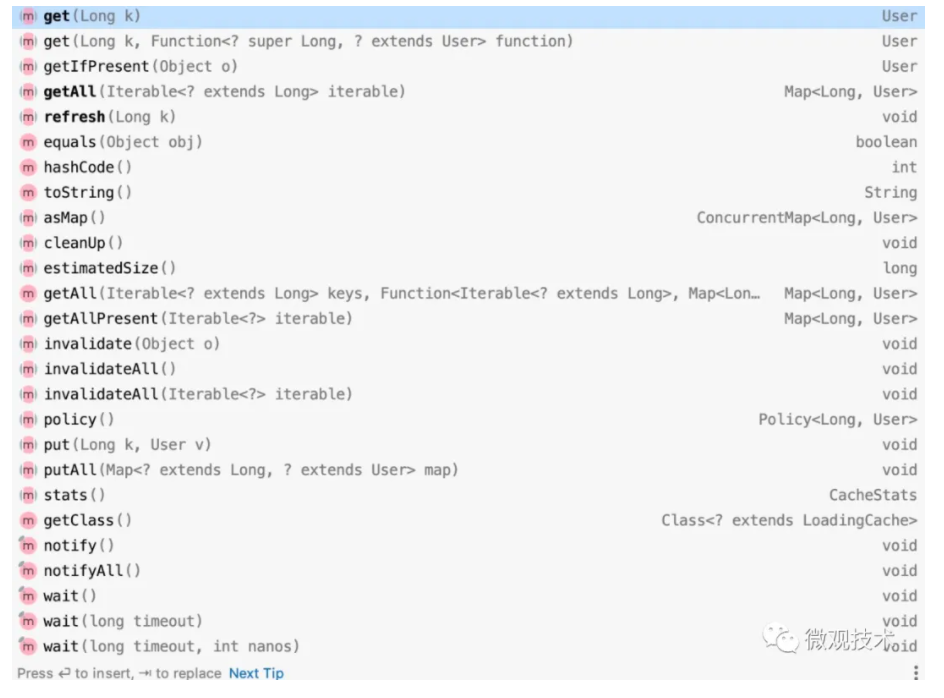
关于Caffine Cache 的各种参数设置,以及常用的API在各种场景下如何使用演示测试
@RunWith(SpringRunner.class)
@SpringBootTest(classes = StartApplication.class)
@FixMethodOrder(MethodSorters.NAME_ASCENDING)
public class CacheServiceTest {
/**
* .refreshAfterWrite(6,TimeUnit.SECONDS)
* .build(id -> {
* Thread.sleep(2_000);
* System.out.println("缓存未命中,从数据库加载,用户id:" + id);
* return User.builder().id(id).userName("Lily").age(new Random().nextInt(20)).build();
* });
*/
@Test
public void test1_refreshAfterWrite() throws ExecutionException, InterruptedException {
User user1 = LocalCacheService.loadingCache.get(1L);
System.out.println("第1次查user1:" + user1);
Thread.sleep(10_000);
// 缓存不存在,返回旧值,并触发缓存刷新
user1 = LocalCacheService.loadingCache.get(1L);
System.out.println("第2次查user1:" + user1);
Thread.sleep(5_000);
user1 = LocalCacheService.loadingCache.get(1L);
System.out.println("第3次查user1:" + user1);
}
/**
* .expireAfterWrite(4, TimeUnit.SECONDS)
* .expireAfterAccess(10,TimeUnit.SECONDS)
*/
@Test
public void test2() throws ExecutionException, InterruptedException {
User user1 = LocalCacheService.loadingCache.get(1L);
System.out.println("第1次查user1:" + user1);
Thread.sleep(6_000);
user1 = LocalCacheService.loadingCache.get(1L);
System.out.println("第2次查user1:" + user1);
}
/**
* 容量上限是10,超过容量会LRU置换
* maximumSize(10)
*/
@Test
public void test3() throws ExecutionException, InterruptedException {
for (int i = 1; i < 16; i++) {
User user1 = LocalCacheService.loadingCache.get(Long.valueOf(i));
System.out.println(String.format("第%s次查user:%s", i, user1));
}
Thread.sleep(30_000);
}
}
缓存填充策略
缓存的填充方式有三种,手动、同步和异步
1、手动加载
手动将值放入缓存后再检索
cache.put(key, dataObject);
dataObject = cache.getIfPresent(key);
我们可以通过 cache.getIfPresent(key) 方法来获取一个key的值,通过cache.put(key, value)方法显示的将数值放入缓存,但是这样会覆盖缓原来key的数据。
建议使用cache.get(key,k - > value) 的方式,get 方法将一个参数为 key 的 Function (createExpensiveGraph) 作为参数传入。如果缓存中不存在该键,则调用这个 Function 函数,并将返回值作为该缓存的值插入缓存中。get 方法是以阻塞方式执行,即使多个线程同时请求该值也只会调用一次Function方法。这样可以避免与其他线程的写入竞争,这也是为什么使用 get 优于 getIfPresent 的原因。
2、同步加载
这种加载缓存方式使用了与用于初始化值的 Function 的手动策略类似的 get 方法。让我们看看如何使用它。
Caffeine.newBuilder()
.maximumSize(10)
.build(id -> {
System.out.println("缓存未命中,从数据库加载,用户id:" + id);
return User.builder().id(id).userName("Lily").age(new Random().nextInt(20)).build();
});
3、异步加载
此策略与同步加载相似,但是以异步方式执行操作,并返回一个包含值的 CompletableFuture
AsyncLoadingCache
.maximumSize(10)
.buildAsync(id -> {
System.out.println("缓存未命中,从数据库加载,用户id:" + id);
return User.builder().id(id).userName("Lily").age(new Random().nextInt(20)).build();
});
驱逐策略(eviction)
Caffeine提供三类驱逐策略:基于大小(size-based),基于时间(time-based)和基于引用(reference-based)。
1、基于大小(size-based)
基于大小驱逐,有两种方式:一种是基于缓存大小,一种是基于权重。
使用Caffeine.maximumSize(long)方法来指定缓存的最大容量。当缓存超出这个容量的时候,会使用Window TinyLfu策略来删除缓存。
也可以使用权重的策略来进行驱逐,可以使用Caffeine.weigher(Weigher) 函数来指定权重,使用Caffeine.maximumWeight(long)函数来指定缓存最大权重值。
maximumWeight 与 maximumSize 不可以同时使用。
2、基于时间(Time-based)
Caffeine提供了三种定时驱逐策略:
expireAfterAccess(long, TimeUnit):在最后一次访问或者写入后开始计时,在指定的时间后过期。假如一直有请求访问该key,那么这个缓存将一直不会过期。
expireAfterWrite(long, TimeUnit):在最后一次写入缓存后开始计时,在指定的时间后过期。
expireAfter(Expiry):自定义策略,过期时间由Expiry实现独自计算。
3、基于引用(reference-based)
我们可以将缓存的驱逐配置成基于垃圾回收器。为此,我们可以将key 和 value 配置为弱引用或只将值配置成软引用。
图片
注意:AsyncLoadingCache不支持弱引用和软引用。
Caffeine.weakKeys() 使用弱引用存储key。如果没有其他地方对该key有强引用,那么该缓存就会被垃圾回收器回收。由于垃圾回收器只依赖于身份(identity)相等,因此这会导致整个缓存使用身份 (==) 相等来比较 key,而不是使用 equals()。
Caffeine.weakValues() 使用弱引用存储value。如果没有其他地方对该value有强引用,那么该缓存就会被垃圾回收器回收。由于垃圾回收器只依赖于身份(identity)相等,因此这会导致整个缓存使用身份 (==) 相等来比较 key,而不是使用 equals()。
Caffeine.softValues() 使用软引用存储value。当内存满后,软引用的对象使用最近最少使用(least-recently-used ) 的方式进行垃圾回收。由于使用软引用是需要等到内存满了才进行回收,所以我们通常建议给缓存配置一个使用内存的最大值。softValues() 将使用身份相等(identity) (==) 而不是equals() 来比较值。
注意:Caffeine.weakValues()和Caffeine.softValues()不可以一起使用。
手动删除缓存
任何时候,你都可以主动使缓存失效,而不用等待缓存被驱逐
// 单个key
cache.invalidate(key)
// 批量key
cache.invalidateAll(keys)
// 所有key
cache.invalidateAll()
统计
Cache
.maximumSize(10_000)
.recordStats()
.build();
通过使用Caffeine.recordStats(), 可以转化成一个统计的集合。通过 Cache.stats() 返回一个CacheStats。CacheStats提供以下统计方法:
hitRate():返回缓存命中率
evictionCount():缓存回收数量
averageLoadPenalty():加载新值的平均时间
演示代码地址
https://github.com/aalansehaiyang/spring-boot-bulking
模块:spring-boot-bulking-caffeine
正文到此结束